逆天了!麻省理工专家们整出会编程的程序
给一个三岁的孩子看一辆三轮车,并告诉他这是三轮车,以后这个孩子看到类似的车辆都能知道是三轮车。但是如果要教会一台电脑什么是三轮车,可能要给它看成千上万的三轮车,他才能学会。
这就是电脑和人脑的差别。无论是那种计算机深度学习,或者具体的面部识别功能,都需要大量的样本分析才能做到一定的识别率。
但现在,据 Fortune 报道,纽约大学、麻省理工学院和多伦多大学的研究人员建立了一个新的模型,让电脑能学一次就举一反三的理解更多类似的东西。比如通过理解一张照片的内容来识别这张图片的含义,而不是把这张照片的内容跟数据库里成千上万的照片对比才能得出结论。
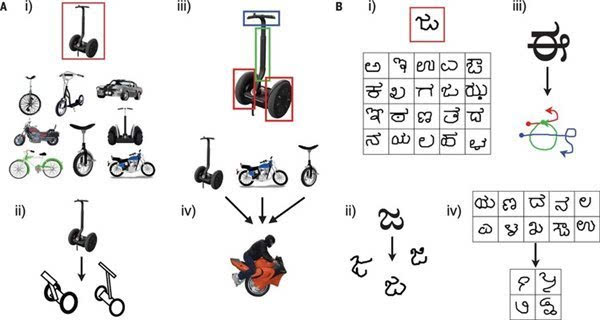
BPL会对图片中平衡车的不同部分进行分解,从而学习图中什么是平衡车,然后举一反三识别更多平衡车甚至创造其他不同的平衡车。对文字也是一样。
他们将这个研究成果发表在了《科学》杂志上。这个数据模型叫做BPL (Bayesian Program Learning贝叶斯程序学习)。 简单来说,这个程序能通过对现有程序的再次利用、捕捉真实世界里的组合及因果关系来自行建立一个新的程序, 而不是像其他深度学习程序那样依赖大量的重复。这和人们认识新事物的学习过程非常相似。
比如对文字的识别,现在的机器学习会识别每一个像素,然后和数据库里的文字做比较。而BPL则能从更概念的层面来识别文字,比如识别一个文字的基本结构,把文字看成是各种笔划的组合——人们识字(尤其是抄写文字的时候)也是如此。
从这个概念出发,这种人工智能能够找到自己写字的方法,比如能读懂各种标识、增加语音识别的准确率,最终甚至可以建立军事模型。
相比大量的重复学习,BPL的学习方法更为高效和智能。现在的研究人员的实验还停留在图片识别和写简单文字符号阶段,但如果算法不断得到完善,它会变得越来越像一个真正具有智慧的人脑。
最新内容
热点内容
 QQ群
QQ群

- 编程新手
17243348


- 编程爱好者
179619951

- WEB编程开发
19713232
-
 微信
微信

-
 返回首页
返回首页 -
 返回顶部
返回顶部