Java 线程池详细介绍
根据摩尔定律(Moore’s law),集成电路晶体管的数量差不多每两年就会翻一倍。但是晶体管数量指数级的增长不一定会导致 CPU 性能的指数级增长。处理器制造商花了很多年来提高时钟频率和指令并行。在新一代的处理器上,单线程程序的执行速率确实有所提高。但是,时钟频率不可能无限制地提高,如处理器 AMD FX-9590 的时钟频率达到5 GHz,这已经非常困难了。如今处理器制造商更喜欢采用多核处理器(multi-core processors)。拥有4核的智能手机已经非常普遍,更不用提手提电脑和台式机。结果,软件不得不采用多线程的方式,以便能够更好的使用硬件。线程池可以帮助程序员更好地利用多核 CPU。
线程池
好的软件设计不建议手动创建和销毁线程。线程的创建和销毁是非常耗 CPU 和内存的,因为这需要 JVM 和操作系统的参与。64位 JVM 默认线程栈是大小1 MB。这就是为什么说在请求频繁时为每个小的请求创建线程是一种资源的浪费。线程池可以根据创建时选择的策略自动处理线程的生命周期。重点在于:在资源(如内存、CPU)充足的情况下,线程池没有明显的优势,否则没有线程池将导致服务器奔溃。有很多的理由可以解释为什么没有更多的资源。例如,在拒绝服务(denial-of-service)攻击时会引起的许多线程并行执行,从而导致线程饥饿(thread starvation)。除此之外,手动执行线程时,可能会因为异常导致线程死亡,程序员必须记得处理这种异常情况。
即使在你的应用中没有显式地使用线程池,但是像 Tomcat、Undertow这样的web服务器,都大量使用了线程池。所以了解线程池是如何工作的,怎样调整,对系统性能优化非常有帮助。
线程池可以很容易地通过 Executors 工厂方法来创建。JDK 中实现 ExecutorService 的类有:
- ForkJoinPool
- ThreadPoolExecutor
- ScheduledThreadPoolExecutor
这些类都实现了线程池的抽象。下面的一小段代码展示了 ExecutorService 的生命周期:
public List<Future<T>> executeTasks(Collection<Callable<T>> tasks) {
// create an ExecutorService
// 创建 ExecutorService
final ExecutorService executorService = Executors.newSingleThreadExecutor();
// execute all tasks
// 执行所有任务
final List<Future<T>> executedTasks = executorService.invokeAll(tasks);
// shutdown the ExecutorService after all tasks have completed
// 所有任务执行完后关闭 ExecutorService
executorService.shutdown();
return executedTasks;
}
首先,创建一个最简单的 ExecutorService —— 一个单线程的执行器(executor)。它用一个线程来处理所有的任务。当然,你也可以通过各种方式自定义 ExecutorService,或者使用 Executors 类的工程方法来创建 ExecutorService:
newCachedThreadPool() :创建一个 ExecutorService,该 ExecutorService 根据需要来创建线程,可以重复利用已存在的线程来执行任务。
newFixedThreadPool(int numberOfThreads) :创建一个可重复使用的、固定线程数量的 ExecutorService。
newScheduledThreadPool(int corePoolSize):根据时间计划,延迟给定时间后创建 ExecutorService(或者周期性地创建 ExecutorService)。
newSingleThreadExecutor():创建单个工作线程 ExecutorService。
newSingleThreadScheduledExecutor():根据时间计划延迟创建单个工作线程 ExecutorService(或者周期性的创建)。
newWorkStealingPool():创建一个拥有多个任务队列(以便减少连接数)的 ExecutorService。
在上面这个例子里,所有的任务都只执行一次,你也可以使用其他方法来执行任务:
- void execute(Runnable)
- Future submit(Callable)
- Future submit(Runnable)
最后,关闭 executorService。Shutdown() 是一个非阻塞式方法。调用该方法后,ExecutorService 进入“关闭模式(shutdown mode)”,在该模式下,之前提交的任务都会执行完成,但是不会接收新的任务。如果想要等待任务执行完成,需要调用 awaitTermination() 方法。
ExecutorService 是一个非常有用的工具,可以帮助我们很方便执行所有的任务。它的好处在什么地方呢?我们不需要手动创建工作线程。一个工作线程就是 ExecutorService 内部使用的线程。值得注意的是,ExecutorService 管理线程的生命周期。它可以在负载增加的时候增加工作线程。另一方面,在一定周期内,它也可以减少空闲的线程。当我们使用线程池的时候,我们就不再需要考虑线程本身。我们只需要考虑异步处理的任务。此外,当出现不可预期的异常时,我们不再需要重复创建线程,我们也不需要担心当一个线程执行完任务后的重复使用问题。最后,一个任务提交以后,我们可以获取一个未来结果的抽象——Future。当然,在 Java 8中,我们可以使用更优秀的 CompletableFuture,如何将一个 Future 转换为 CompletableFuture 已超出了本文所讨论的范围。但是请记住,只有提交的任务是一个 Callable 时,Future 才有意义,因为 Callable 有输出结果,而 Runnable 没有。
内部组成
每个线程池由几个模块组成:
- 一个任务队列,
- 一个工作线程的集合,
- 一个线程工厂,
- 管理线程状态的元数据。
ExecutorService 接口有很多实现,我们重点关注一下最常用的 ThreadPoolExecutor。实际上,newCachedThreadPool()、newFixedThreadPool() 和 newSingleThreadExecutor() 三个方法返回的都是 ThreadPoolExecutor 类的实例。如果要手动创建一个ThreadPoolExecutor 类的实例,至少需要5个参数:
- int corePoolSize:线程池保存的线程数量。
- int maximumPoolSize:线程的最大数量。
- long keepAlive and TimeUnit unit:超出 corePoolSize 大小后,线程空闲的时间到达给定时间后将会关闭。
- BlockingQueue workQueue:提交的任务将被放置在该队列中等待执行。
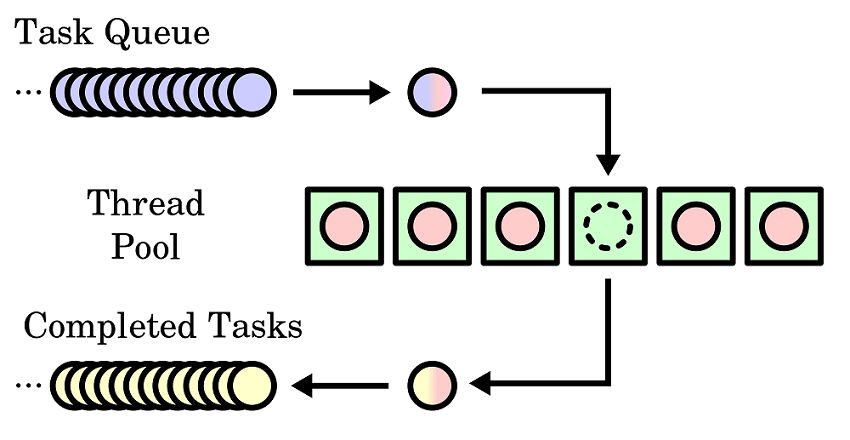
阻塞队列
LinkedBlockingQueue 是调用 Executors 类中的方法生成 ThreadPoolExecutor 实例时使用的默认队列,PriorityBlockingQueue 实际上也是一个BlockingQueue,不过,根据设定的优先级来处理任务也是一个棘手的问题。首先,提交一个 Runnable 或 Callable 任务,该任务被包装成一个 RunnableFuture,然后添加到队列中,ProrityBlockingQueue 比较每个对象来决定执行的优先权(比较对象是包装后的RunnableFuture而不是任务的内容)。不仅如此,当 corePoolSize 大于1并且工作线程空闲时,ThreadPoolExecutor 可能会根据插入顺序来执行,而不是 PriorityBlockingQueue 所期望的优先级顺序。
默认情况下,ThreadPoolExecutor 的工作队列(workQueue)是没有边界的。通常这是没问题的,但是请记住,没有边界的工作队列可能导致应用出现内存溢出(out of memory)错误。如果要限制任务队列的大小,可以设置 RejectionExecutionHandler。你可以自定义处理器或者从4个已有处理器(默认AbortPolicy)中选择一个:
- CallerRunsPolicy
- AbortPolicy
- DiscardPolicy
- DiscardOldestPolicy
线程工厂
线程工厂通常用于创建自定义的线程。例如,你可以增加自定义的 Thread.UncaughtExceptionHandler 或者设置线程名称。在下面的例子中,使用线程名称和线程的序号来记录未捕获的异常。
public class LoggingThreadFactory implements ThreadFactory {
private static final Logger logger = LoggerFactory.getLogger(MethodHandles.lookup().lookupClass());
private static final String THREAD_NAME_PREFIX = "worker-thread-";
private final AtomicInteger threadCreationCounter = new AtomicInteger();
@Override
public Thread newThread(Runnable task) {
int threadNumber = threadCreationCounter.incrementAndGet();
Thread workerThread = new Thread(task, THREAD_NAME_PREFIX + threadNumber);
workerThread.setUncaughtExceptionHandler(thread, throwable -> logger.error("Thread {} {}", thread.getName(), throwable));
return workerThread;
}
}
生产者消费者实例
生产者消费者是一种常见的同步多线程处理问题。在这个例子中,我们使用 ExecutorService 解决此问题。但是,这不是解决该问题的教科书例子。我们的目标是演示线程池来处理所有的同步问题,从而程序员可以集中精力去实现业务逻辑。
Producer 定期的从数据库获取新的数据来创建任务,并将任务提交给 ExecutorService。ExecutorService 管理的线程池中的一个工作线程代表一个 Consumer,用于处理业务任务(如计算价格并返回给客户)。
首先,我们使用 Spring 来配置:
@Configuration
public class ProducerConsumerConfiguration {
<a href='http://www.jobbole.com/members/weibo_1902876561'>@Bean</a>
public ExecutorService executorService() {
// single consumer
return Executors.newSingleThreadExecutor();
}
// other beans such as a data source, a scheduler, etc.
}
然后,建立一个 Consumer 及一个 ConsumerFactory。该工程方法通过生产者调用来创建一个任务,在未来的某一个时间点,会有一个工作线程执行该任务。
public class Consumer implements Runnable {
private final BusinessTask businessTask;
private final BusinessLogic businessLogic;
public Consumer(BusinessTask businessTask, BusinessLogic businessLogic) {
this.businessTask = businessTask;
this.businessLogic = businessLogic;
}
@Override
public void run() {
businessLogic.processTask(businessTask);
}
}
@Component
public class ConsumerFactory {
private final BusinessLogic businessLogic;
public ConsumerFactory(BusinessLogic businessLogic) {
this.businessLogic = businessLogic;
}
public Consumer newConsumer(BusinessTask businessTask) {
return new Consumer(businessTask, businessLogic);
}
}
最后,有一个 Producer 类,用于从数据库中获取数据并创建业务任务。在这个例子中,我们假定 fetchData() 是通过 scheduler 周期性调用的。
@Component
public class Producer {
private final DataRepository dataRepository;
private final ExecutorService executorService;
private final ConsumerFactory consumerFactory;
@Autowired
public Producer(DataRepository dataRepository, ExecutorService executorService,
ConsumerFactory consumerFactory) {
this.dataRepository = dataRepository;
this.executorService = executorService;
this.consumerFactory = consumerFactory;
}
public void fetchAndSubmitForProcessing() {
List<Data> data = dataRepository.fetchNew();
data.stream()
// create a business task from data fetched from the database
.map(BusinessTask::fromData)
// create a consumer for each business task
.map(consumerFactory::newConsumer)
// submit the task for further processing in the future (submit is a non-blocking method)
.forEach(executorService::submit);
}
}
非常感谢 ExecutorService,这样我们就可以集中精力实现业务逻辑,我们不需要担心同步问题。上面的演示代码只用了一个生产者和一个消费者。但是,很容易扩展为多个生产者和多个消费者的情况。
总结
JDK 5 诞生于2004年,提供很多有用的并发工具,ExecutorService 类就是其中的一个。线程池通常应用于服务器的底层(如 Tomcat 和 Undertow)。当然,线程池也不仅仅局限于服务器环境。在任何密集并行(embarrassingly parallel)难题中它们都非常有用。由于现在越来越多的软件运行于多核系统上,线程池就更值得关注了。
最新内容
热点内容
 QQ群
QQ群

- 编程新手
17243348


- 编程爱好者
179619951

- WEB编程开发
19713232
-
 微信
微信

-
 返回首页
返回首页 -
 返回顶部
返回顶部